

Imagine how much easier learning to read (and teaching reading) would be if the words learners learn to read with were also word-learning-help buttons. Imagine how more neurologically efficient and emotionally safe learning would be if every unfamiliar word had a built-in reading tutor, language translator, and reference library. Instead of imagining it, try it. Every word on this page is its own word-learning-help button.
 All current methods of reading instruction are based on some variation of explicitly teaching abstract knowledge and skills for code processing and/or scaffolding up the complexity of relevantly meaningful content as an environment for implicitly learning to process the code.
All current methods of reading instruction are based on some variation of explicitly teaching abstract knowledge and skills for code processing and/or scaffolding up the complexity of relevantly meaningful content as an environment for implicitly learning to process the code.
Despite their huge differences, these systems share a common assumption; they assume that written words are static objects that can’t in and of themselves help readers learn to read them. This was understandable when paper was the only media available for reading instruction. However, in light of today’s technologies, it’s time to challenge that assumption. While good readers must be able to eventually read static text, nothing (except centuries of inertia*) says we have to use static text to teach beginning and struggling readers.
*Before proceeding please consider this short background: How Do Kids Learn to Read? What the Science DOESN’T SAY.
Reading is an artificial language experience constructed by our brains according to the instructions and information contained in a c-o-d-e. Though many factors contribute to difficulties in learning to read, what makes learning to read (English and other deep orthographies) difficult for most beginning and struggling readers – what initially challenges their brains – is the confusing relationship between the naturally evolved and naturally learned code of speaking and listening, and the artificially created and artificially learned c-o-d-e of reading and writing. (See: Unnatural Confusion)
It’s one of the most complex, unnatural, cognitive interactions that brain and environment have to coalesce together to produce. – Dr. G. Reid Lyon, Past-Chief of the Child Development and Behavior Branch of the National Institute of Child Health & Human Development, National Institutes of Health,
The c-o-d-e of English orthography is an archaic legacy technology (like telegraphs and typewriters). However, unlike modern information technologies, there wasn’t a committee of designers concerned with developing its ‘user interface’ so it would be easy for people to learn to use. Instead, English orthography is the result of elitism, prejudice, ignorance, negligence, and a series of historical accidents (See: The First Millennium Bug).
“It’s easy to forget that the system we have learned is a system that is based on a series of accidents that result in layers of complexity”– Dr. Thomas Cable, Co-author: A History of the English Language
Many notables, including Benjamin Franklin, Noah Webster, Melvil Dewey, Theodore Roosevelt, and Mark Twain, recognized that the code’s letter-sound confusion was at the root of reading difficulties. Yet, despite their efforts, and those of hundreds of others, centuries of attempts to change the alphabet or reform English spelling – to render their relationship more simply phonetic – failed (See: Reform Attempts).
“Delay in the plan here proposed may be fatal… the minds of men may again sink into indolence; a national acquiescence in error will follow, and posterity be doomed to struggle with difficulties which time and accident will perpetually multiply”. – Noah Webster
The central issue is inertia. Any change to the alphabet or spelling would create a ‘before’ and ‘after’ disconnect in the continuity of written English; and would be a disturbance, nuisance, and expense to everyone literate in the system as it is now.
“People are more likely to change their religion than change their writing system.” – Charles Hockett, Anthropological Linguist
Because changing the code – changing the alphabet or spelling – has such intolerable consequences, our conceptions of ‘teaching reading’ have been constrained to accepting the confusion as immutable. As a consequence, virtually everything we think about reading, learning to read, and the teaching of reading (including “Scientifically Based Reading Research“), is based on – warped by – accepting the code’s letter-sound-spelling confusion as immutable (See: Paradigm Inertia). All traditional approaches to teaching reading are based on training the brains of readers to deal with this letter-sound confusion by either working around it (whole – contextual guessing) or by recognizing rule-clues (cues) in the letter’s lexical and semantic context (phonics). Phonics and whole language methods are both attempts to compensate for (workaround), rather than directly address, the confusing correspondence between letters and sounds.
…[in English] “we have fifty some sounds and only twenty-six letters. So we have to adopt a whole variety of mechanisms to close the gap.” – Dr. Richard Venezky, Author: The American Way of Spelling: The Structure and Origins of American English Orthography
We can’t change the alphabet or change the ways we spell with it. However, today, in an era of ever less expensive and increasingly more powerful digital devices, we can use modern technology to dynamically personalize, scaffold, and differentiate the process of learning to read. Once we make words hyper-orthographic, rather than static-orthographic, the technology can guide students through learning to read in profoundly more efficient ways.
The purpose of reading instruction is to teach students how to work out words they don’t know. Because teachers can’t be on the ‘live edge of learning to read’ with all of their students all the time, and because static printed words can’t provide students any help in recognizing them, our models of reading instruction have been limited to training students to remember and apply abstract rules and procedures to work out words on their own. This is where it all breaks down. The reason reading instruction fails so many students is because it’s not available to them when they most need it – when, while trying to read, they encounter a word they don’t know. But what if it was available?
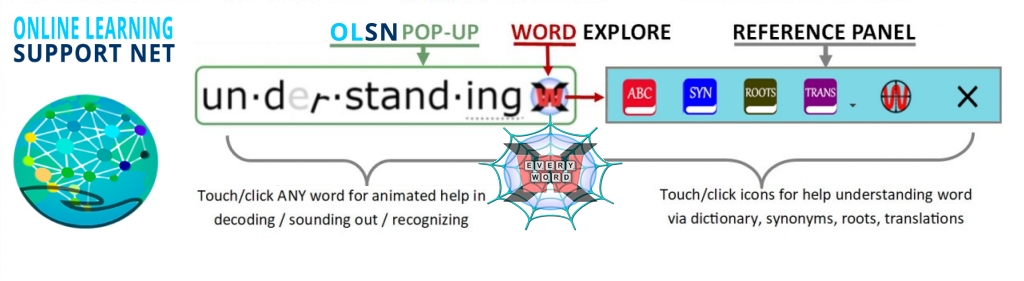
Instead of teaching learners to decode / recognize words by using abstract instructional exercises (and hoping they will apply them reliably fast enough when they are later actually reading), interactive orthography makes it possible to provide focused and granular instruction while learners are actually engaged in the live act of trying to read words. Not some words some of the time, but each and every word that stutters the flow of their reading.
Using today’s inexpensive digital technology we can add another ‘learner’s layer’ to English orthography. We can preserve the two-dimensional alphabet and spelling, and digitally embed within it a dynamically responsive layer that provides a profoundly more neurologically efficient way to learn to read or improve reading. Instead of pedagogy constrained by the limitations of ‘static-orthography’, we can completely re-imagine literacy learning through the lens of what interactive orthography makes possible.
Such a ‘learner’s orthography’ is able to respond; letter-by-letter, sound-by-sound, word-by-word, meaning by meaning, with whatever learners need as they progress to fluency in reading. Not just read the words for them (short-circuiting their learning), rather, interactively scaffold, in real-time, the process of learners learning to work out recognizing and understanding the word for themselves. With hyper-orthographic support, beginning and struggling readers learn with LIVE dynamic text that instructs, guides, and supports them word-by-word, not only to recognize and understand each and every particular word they ‘stutter’ on, but in a way that generalizes to learning to read all words.
Sound far-fetched? Click on any word on this page!
Our debates about reading instruction are rooted in assumptions about the orthographic technology we learn to read with (consider this short background: Paradigm Inertia In Reading Science and Policy). By adding a dynamic overlay to the orthography, we can preserve the best and eliminate the worst of phonics and whole language as we differentially support and scaffold learners up a more learning-friendly ladder to proficient reading.
Why not? Twenty-five years of ‘reading war’ debates, thousands of research papers, hundreds of billion of dollars…. and yet most of our children are still below proficient in reading in school:



Independent Learners – Home – Classroom – School Library – Public Library
Three simple steps to reading: How to use OLSN with your students
![]() Install Free App: With the OLSN Chrome Extension, Interactive Orthography works on billions of pages on the internet, including most of the largest educational content sites:
Install Free App: With the OLSN Chrome Extension, Interactive Orthography works on billions of pages on the internet, including most of the largest educational content sites:

 With a few lines of code, Interactive Orthography can be easily added to websites, web pages, blogs, e-books, and apps. Interactive Orthography can be added to public non-profit content/sites for free. It can be added to subscription and fee based content, sites, and apps for a small fee. Click here to talk with us about adding the Interactive Orthography API to your content or application.
With a few lines of code, Interactive Orthography can be easily added to websites, web pages, blogs, e-books, and apps. Interactive Orthography can be added to public non-profit content/sites for free. It can be added to subscription and fee based content, sites, and apps for a small fee. Click here to talk with us about adding the Interactive Orthography API to your content or application.
![]()
1 – Compared with the cost of ineffective reading instruction, the cost of providing inexpensive platforms that can provide hyper-orthographic learning to read support is trivial.
This is great! I wish I found this when I was in school. Thank you for creating this.
It would be more helpful if the word were divided according to actual syllable division rules. Rec – og – ni – zing NOT re-cog-niz-ing. The rules of our code should apply. The e is a short vowel because it is in a syllable closed by a consonant. The i is long because it is in an open syllable – one that ends with the vowel. (This is the way the C-O-D-E works.)
It would also be more helpful if the syllables were sounded and blended individually, then blended in syllable chunks. It is too big a load on working memory to hold on to 8 or 9 phonemes and then blend them. /r/ /e/ /k/ “rec” /o/ /g/ “og” /n/ /i/ “ni” /z/ /i/ /ng/ “zing” rec- og – ni – zing –> recognizing.
This is how we use phonics to teach children to unlock long words and software that reinforces this would be more helpful than software that contradicts it.
Thank you, Marilyn. Your comment is very much appreciated and respected. I hope you will continue to engage in this dialogue and help us learn to be better stewards of the process of learning to read.
Before I respond to your excellent criticism, let’s begin with agreeing that we are both people with good intentions. By that I mean we are not motivated by financial or psychological profit, instead by a deep and genuine intent to be stewards of the learning wellness of children. We both acknowledge there is a lot at stake. If we agree so far, let’s respect each other and carefully learn together.
Your criticism focuses on an important but secondary aspect of Interactive Orthography so before I respond to it, let me make sure we have some degree of shared understanding about the primary aspect.
Interactive orthography, is a new kind of media/medium for learning to read and/or for learning new languages and/or for learning new vocabulary and/or for supporting any and all of those aspects during reading to learn.
Making orthography (which is already complexly virtual) digital makes it possible to intelligently, adaptively, interactively, instruct, guide, and resource learners during their live participation on the real-time edge of learning to read. It’s as different from static orthography (inert two-dimensional print (paper, or screen)) as a smartphone is from a rotary phone – as the internet is from a typewriter. Just as we wouldn’t limit the design of email apps to the mechanics of how typewriters type characters, it’s important to not limit our thoughts about reading instruction to what is and isn’t possible with static orthography. After all, everything about the prevailing “science of reading”, and how it’s translated into instructional models, is based on what is and isn’t possible with static orthography. That is to say, defined by the assumption that at the instant a learner’s mind “stutters” while trying to recognize a word, the learner is alone – the word itself can’t help. The prevailing model is based on training the learner’s mind to respond to that instant of word uncertainty by remembering and performing mental routines.
Now, as an example, let’s look at what you shared.
It would be more helpful if the word were divided according to actual syllable division rules. Rec – og – ni – zing NOT re-cog-niz-ing. The rules of our code should apply. The e is a short vowel because it is in a syllable closed by a consonant. The i is long because it is in an open syllable – one that ends with the vowel. (This is the way the C-O-D-E works.)
With all respect, NO it isn’t. This the way you have learned to make the static c-o-d-e work. Implicitly this model demands that children learn to reflexively apply machine-like abstract rules to the process of decoding. The only reason we’d even consider such an abstract processing demand is because of the irregularities in English orthography. [See this video of Professor Stanislas Dehaene (Reading in the Brain) discussing why Italian be learned in 3 months and it takes 3 years to learn English https://www.facebook.com/childrenofthecode/videos/2540144202872137/]
ONCE we have interactive orthography as our info-tech-medium for learning to read we no longer need to explicitly teach abstract complex rules as a basis for decoding. Interactive orthography doesn’t require readers to recognize morphemes as an interpretive overlay to decoding letter sounds. So for example, just on the simplest level of reducing vowel sound ambiguity, we render vowels bold when they are long, we shrink them when they are schwas, we leave them alone when they are short, and we grey them out when they are silent (see PQs light). We deal with letter sound ambiguity in a completely different (and profoundly more neurologically efficient) way that doesn’t involve segmentation.
Marilyn, we have no attachment to how to segment a word. We agree that the way we are segmenting words is unconventional, but it’s not sloppy. We have our reasons. Here is why we did it the way we did:
[click on the word “recognize”, look and listen. Click it again. Look and listen. Again…. until you hear it normally spoken]
“re” again, “cog” (the key cognate in the word), as to where to split niz-ing, “ing” is a high frequency recurring unit and ‘ize’ is a morpheme to “to render, to make”. Thus our segmentation, we would argue, breaks the words into more readily recognizable sub sounds while also drawing attention to the morphological structure (rather than warping the morphology around cueing sounds as is the case in your example: rec/og/ni/zing).
Again we are not attached here. Our key distinction is the difference between “static” orthography (inert print) and “interactive” orthography (dynamic multi-sensory interaction based scaffolding for learning to recognize and understand words). In static orthography the reader’s brain must be trained to use a variety of complex abstract methods to attack unknown words and work them out. With interactive orthography the reader need only click on unknown words to be guided through a ‘working out’ of the words pronunciation and recognition. We are first and foremost about making the neurological efficiency case for making orthography interactive. Once we can agree on that, and once we have the PQ Pop-up teaching letter-sound patterns it’s an open question how we should reimagine segmentation in light of it no longer having to assist decoding.
With appreciation and respect, I invite you to join with me in learning together to tune this different way of thinking. Let’s talk about the issues you raise and explore how we might make our tools feel less alien to those trained in the existing system. Maybe we should conform to existing segmentation logic to make the overall system easier to embrace. Maybe we should completely re-think segmentation logic around the new role segmentation plays in our kind of system. We are open to learning to evolve this to the benefit of the kids. Will you learn into this with us? I sincerely hope so.
this idea might have potential but unfortunately the transcription system used here is one of the most poorly designed phonetic transcription systems for English I’ve ever seen. as an example, the transcription for “spelling” (and the way it’s sounded out when clicked on) claims that the E and the second L are both silent, and that the first L on its own is pronounced as /ɛl/. why? that’s so much actively worse than the real explanation for why it’s pronounced the way it is. a system which allows children to click on a word and be shown how to sound it out is a good idea, but ideally that system should actually, you know, show how to sound out words instead of whatever this backwards system is trying to do.
Thanks Jan we appreciate your engagement.
First, we welcome dialogue as to HOW the visual cues we use could best support learning to disambiguate > decode. Your question about spelling reveals a bias in thinking caused by your static conception of the orthography. If rather than using this real time responsive learning support system to augment the way we have historically thought about reading instruction, we reimagine reading instruction in terms of what this kind of technology and approach makes possible, the question answers itself. The bottleneck to progress and the cause of great difficulty during the process of learning to read in English is the artificially complexly confusing relationships between letters and sounds. (Watch Stanislas Dehaene present on this point: https://bit.ly/2YwISa1). Most kids learn letters in ways that prime their brains to reflexively respond to the sight of a letter with its name (Hebbian learning – neuron wire and fire:https://childrenofthecode.org/interviews/tallal.htm#how-the-brain-learns). When learning the alphabet letters there is no such thing as silent letters. Given the learned biases in play at the time children are learning to read, helping them know when a letter is silent (not heard) or sounds like its letter name significantly reduces their confusion (https://mlc.learningstewards.org/logic-of-pqs/) without requiring them to remember to apply unnaturally abstract interpretation rules. Do you hear the “e” in spelling? Do you hear the second “l” in spelling? No. You think you need to spell those sounds that way. If you get what I am talking about and from a fresh place want to dialogue with us about how to improve how we represent the letter-sound patterns and use them to conduct the kind of on-demand learning we are advocating, I’d welcome the opportunity.
do I hear the E in spelling? do you not? the E in spelling is pronounced as it is in “bed” and “dress” and “get”. telling a child the E is silent in spelling (or indeed the E in dress, which this system also does) is, in fact, the opposite of helpful. without even mentioning the several words where the pronunciation this system suggests is just completely wrong (pizza, hiccough, few, pinata) or how there’s no indication at all that some words have multiple equally valid pronunciations (you say tomato, everyone else says tomato! also there’s the cot-caught merger) the general design of this transcription system is just bad.
You did manage to pick some two examples (hiccough and pinata) where our system doesn’t do a good job (and no system does). How do you represent and explain the “ya” sound in pinata or the ending “up” sound in “hiccough”? No system is perfect, the orthography is too bizarrely convoluted for that. The challenge is to significantly reduce the confusion THE LEARNER EXPERIENCES (not the already literate mind imagines). Our system reduces the confusion in about 100,000 English words. I can understand and engage in a conversation about the tactical reasons to make this kind of tech more phonics friendly. However, there is nothing “right” about phonics and insisting you “hear” the “e” in “spelling” is an example of the orthographic paradigm inertia that has caused tens of millions of children to grow up, because they blame themselves for their learning to read difficulties, ashamed of their minds. I’ll take that as a NO to further dialogue.
The core idea could improve the learning experience, that being depedent on its implimentation, some aspects of this system could be improved like the work of the letters in is analyzed as 𝘇𝚎r𝗼, that not maybe not be the best choice in the long run, because it may add more complicated rules into the mind of a kid, ex: a vowel is silent if the following is a consonant that has the sound of it in it’s letter name in start position\a vowel is silent if the before is a consonant that has the sound of it in it’s letter name in end position (Because after the child is familiarized with the idea that letters don’t sound like their letter which I suppose could be fast since most letters in an english sentence don’t sound like their letter name, it may be useless), also \ɚ\ sequences (lEARning) are anlyzed as 𝚅𝘳 and not ᵥr when that would be simpler, perhaps it would be better to use this raised version of the vowels to distingush standard english dental frickatives as in “THat” vs as in “orTHography” (and also as in “eXample” vs as in “aXe”) because while yes most people don’t countiosly think of phonemes in terms of their phonemic properties like manner, voicing, aspiration, It could be that we intuitevely know it, so we could use this resource further to thru intuition make the learner get it faster across their minds!
We could try to reduce the number of “not-normal” letters which may be a more beneficial way of thinking of english spelling taking account a longer period of time:
𝗯єca𝚞sє –> bec𝔞𝔲sє
ʏσ𝘂 –> yᵒʊ (which isn’t my analysis, I analyze it as the group composed of the and the that usually make \aʊ\ like in thOU are making a \u\ sound, but that doesn’t mean that it does not accomplish the desired)
difꜰᵢcul𝘁เєs –> dif̲f̲ᵢculties
e̲n̲glish —> ₑn̲glish (\ɪ\ –> \i\ –> \ɛ\ –> \ɪ\, also I know the exact quality differs but it may be a more predictable patern for the intuition of the people)
Thoroughly intrigued and amazed! This could be a game changer for a lot of students!
Hello David,
I had the same consideration about sounding out by syllables as Marilyn. I totally see your point and agree. I am tutoring two extremely confused children both age 12. I have them use the new M.L. method of attacking words. Yesterday the boy was able to “get” three words using M.L. He totally cannot get traditional phonics. The instruction in M.L. was minimal. I have to take it slow and easy as he has been beaten up trying to learn to read. I was one of his past teachers and did some of the beating up. Which is why he is a pro-bono student now. Yesterday I told him that M.L. will be applied to all computer literature in the future. That is why I am having him learn it. I scan the stories and pick out words. Sometimes he will read a whole sentence. Little by little he is beginning to trust me and M.L. Thanks so much
I have a quick question, how do you deal with the word “zebra”, is it like “z-bra”, as that excludes large portions of how some people pronounce the letter Z, the British exist.
The system, as it is shown here, is biased to American English so “zebra” does sound like “z-bra” or (“ZEE”>”BR”>”UH”). The tech is capable of using pronunciation cues adapted to the pronunciation patterns in the population using it. The core is to provide real-time in the flow, during real need (rather than abstractly offline) learning support. The “cues” (the visual variations in letter appearances) are not what’s most important and can eventually morph into whatever works best. The on-demand learning support at the level of the orthography is what we are most concerned with.